三、总体均数的区间估计
由样本统计量推断总体均数有 2 个重要方面:区间估计(interval estimation)和假设检验(hypothesis testing)。先介绍总体均数的区间估计。
仅由样本均数估计总体均数称为点估计(point estimation)。点估计虽然简单,但缺点是未考虑抽样误差。总体均数的区间估计是由抽样误差规律,按一定概率(可信度)估计总体均数在哪个区间(范围),称为总体均
数的可信区间(confidence interval)。其可信度(confidence level)要预先确定。可信度用 1-α表示,常用的可信度为 95%,如要提高可信度则可用 99%。
设正态总体为 N(μ,σ),从中随机抽取含量 n 的样本:X1,X2,⋯, Xn。要由样本估计总体均数μ的 1-α可信区间。
算出样本均数X及其标准误sX ,由(7·18) 式,(X − μ) / sX ,服从
自由度ν=n-1 的 t 分布,因此有
P(−t
α,v
< X − μ < t
X
α,v
) = 1 − α
即 P(X − tα,v sX < μ < X + tα,v sX ) = 1− α
故总体均数μ的 1—α可信区间为
X ± tα,v sX
= X − tα,v sX ~X + tα,v sX
(7·19)
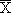 可信区间的
2 个端点值称为可信限(confidence limit), -tα,vs 为可信区间的下限,
+tα,vs
为可信区间的上限。可信区间是指以上、下可信限为界的一个范围,样本均数作为总体均数的点估计处于可信区间中心。
可信区间的
2 个端点值称为可信限(confidence limit), -tα,vs 为可信区间的下限,
+tα,vs
为可信区间的上限。可信区间是指以上、下可信限为界的一个范围,样本均数作为总体均数的点估计处于可信区间中心。
例 7·18 由例 7·2 中某地 10 名 7 岁男孩体重的样本资料,求该地 7 岁男孩体重均数的 95%可信区间。
在例7·2中已算得X = 21.4kg;在例7·17中已算得sX
= 0.8kg。现
ν =n-1=10-1=9 , 1- α =0.95 ,α =0.05 ,查 t 界值表得双侧 t 界值t0.05,9=2.262,故有
21.4±2.262×0.8=19.6~23.2(kg)
该地 7 岁男孩体重均数的 95%可信区间为 19.6~23.2kg。
可信度所指的可信区间包括总体均数的概率是事先对计算可信区间的公
式而言的,如例7·18未抽样本前说X - t 0.05,9 ~X + t 0.05,9 sX 包括总体均数
的概率为 95%。事后抽出样本而得出具体的可信区间就不能那么说了,如例7·18 不能说 19.6~23.2kg 包括总体均数的概率为 95%,因为这时只有两种情况,一是推断正确,总体均数在该区间内;一是推断错误,总体均数在该区间外。而究竟是哪种情况,又不能确定。但是依据一个事件发生的概率可作为该事件实际发生的平均频率的道理,可得出结论:95%可信区间相当每100 个由含量相同的样本算得的可信区间,平均有 95 个可信区间会包括总体
均数,只有 5 个可信区间不会包括总体均数。5%是小概率,实际发生的可能性小,因此实际应用中就认为总体均数在算得的可信区间内,所冒犯错误的风险为 5%。
可信区间估计总体均数的准确度即可信度。估计总体均数的精密度用可信区间的长度(上可信限—下可信限)来衡量比较,该长度越长,精密度越低。要提高估计总体均数的精密度可用加大样本含量来达到。因为 n 加大, 标准误sX 减小(t α,ν 也减小,但影响相对甚微),可信区间的长度变短。
但在样本含量相同的情况下,若要提高估计总体均数的准确度,则必会降低精密度。因为 1—α加大,则α减小,tα,ν加大,可信区间的长度变长。如99%可信区间比 95%可信区间精密度要低。
