第四节 区域地理系统的划分方法一、区域地理系统的划分方法
区域地理系统的均质性划分是传统地理学和现代地理学的主
图 5—5 巴黎城市发展规划
要研究领域,传统地理学是建立在地理比较方法基础上依靠定性的分析描述和选取少数的定量指标进行分区划类,往往不能较好的揭示地理事物本质的空间差异和多因素的组合关系,而带有不同程度的主观随意性。现代地理学则力求通过定性、定量相结合的途径,应用系统科学原理确定综合的多元定量指标,采用数学方法和计算机手段进行地理类型划分和区域划分。在实际工作中,传统方法往往和现代方法同时应用,互相补充,互相印证。
(一)传统划分方法
传统地理学由于对区域地理系统内在联系和变化规律只停留在一般认识上,因此区划方法比较简单,选取的指标体系较为单一,阈值的确定主要凭观察到的地理事实和经验,另外,这种区划一般都具有较强的目的性,因此, 难免有主观因素掺杂其中,每一具体区划都是客观与主观的反映。
1、区划的原则和方法
整个近代地理学时期是以自然区划为主体的,形成了包括发生统一性原则、相对一致性原则、区域共轭性原则、主导因素原则、综合性原则及与之相应的古典法、类型制图法、顺序划分和合并法、主导标志法、地图迭置法与地理相关法在内的一套均质性区划理论体系,均质性的经济类区划及介于二者之间的农业区划,资源区划等也是在这一理论方法框架下进行的。
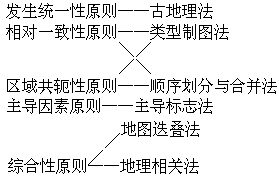
发生统一原则可理解为区划单位系统的古地理分化过程,对自然地理而言,发生统一性不仅是自然综合体形成发展的历史过程的相对一致性,还包含着区域逐级分异的产生的历史过程的相对一致性,由于区域自然综合体的古地理研究是阐明区域分化历史过程的最有效办法,因此发生学原则必须通过古地理法来贯彻。
相对一致性是地理综合体的必要特点,这一原则要求在划分地理综合体时,必须注重其内部的相对一致性,同时这一性质也表现了地理综合体本身都有一定的等级单位系统,因此顺序划分和合并法(即自上而下和自下而上的区划方法)便成为贯彻这一原则的重要方法,类型制图法(根据低级单位的类型单位对比关系进行区划的方法)则是自下而上贯彻这一原则的科学方法。
区域共轭原则是地域上相连接的不同低级区划单位,根据发生联系和物质、能量交换组成高级区划单位的原则,其在自上而下的划分和自下而上的合并中都具有重要意义。贯彻这一原则的相应方法类似于相对一致性原则的方法。
主导因素原则是地理区划中的常用原则,它以选取主导因素作为地理区划的依据,即选取能反映区域分异主导因素的某一指标作为区划界线的主要依据,其优点是使用方便,但由于影响区域形成与分化的是各地理要素间的相互作用,主导因素原则,即主导标志法如使用不当,区划界线难免带有主观性和片面性。
综合性原则是地理区划的重要原则,它要求在进行区划时,必须全面的、综合的分析地理综合体的所有因素,突出地理综合体的“集体效应”,在此基础上找出区域特征及区域分异的主导因素。地理相关法(即比较地理现象的分布图、分析图、区划图,了解区域地理系统的地域分异轮廓,按若干主要因素相互依存关系,制定区域地理系统边界的方法)和地图迭置法(即将若干地理现象的分布图迭置在一起,选择其中重叠最多的线条作为区域地理系统边界的方法)是贯彻这一原则的常用方法。
上述原则和方法在具体地理区划时,多综合交叉使用。2、区划指标与地理阈值的确定
地理阈值也称地理临界值,其主要功能是将地理系统中的不同状态加以分隔与区分。对某一性质的表现范围加以限制和说明,代表着系统状态空间的非连续性。由于地理界线都具有指标含义,所以地理阈值实际上是指标的临界值。传统地理学因为对指标缺少统计处理,故阈值的确定主要以观察、观测到的地理事实和地理学家的经验判断来进行,然后确定指标临界值。如中国综合自然区划(黄秉维,1959)温度带的划分,主要是根据中国东部的作物制度和主要造林树种以及植被、土壤的地域差异划出的。而各温度带积温指标的临界值则是划分后确定的,黄秉维先生称此为“事后诸葛亮”。
从理论上讲,任何区划指标均不能说明区域差异的本质,只能反映主导因素的作用。仍以自然区划为例,它采用的主导指标是反映热量状况的积温和水分状况的干燥度。但应该看到,运用这些指标都存在一些致命弱点,即过于简单,无法刻画动态特征,无法判断界线的位置,缺少严格的数学和物理分析等。因此在应用这些指标时,要充分认识这个问题。
(二)现代划分方法
鉴于上述指标存在的问题,20 世纪 60 年代以后,研究的势头逐渐跌落, 代之而起的将数学方法和计算机手段引入到地理区划中,其目的是为了胜任地理系统变量多,关系复杂所赋予的传统地理学无法完成的任务,当然这些还在探索阶段,但业已形成了包括判别地域分异因素和地理区划等一套数学方法。
1、地域分异的判别因素(主因子分析判别)
主因子分析(PCA)是把一些具有错综复杂关系的因子归结为数量较少的几个综合因子(又称主因子)的一种多元统计分析方法。其目的是在互为关联的许多因子中,找出能反映它们内在联系的和起主导作用的数目较少的新因子,地理系统是由互为关联的许多因子组成,因此主因子分析在区域地理系统研究中有广泛的应用前途。
主因子数学模型在区域地理研究中是从一组资料出发的,已知有 N 个(区
域)样品,每个样品有 P 个变量,则资料矩阵 X 可表示为:
x11 x12 Λ x1D
x x Λ x
X =
21 22 2 D
Λ Λ Λ Λ Λ
x x Λ x
N1 N 2 ND
为了消除区域地理变量之间在数量级上或量纲上的差异,进行主因子分析之前,先对变量进行标准化。以使每个变量的平均值都为 0,方差都为 1。对第 i(i=1, 2,⋯, P)个变量 xi 的标准化公式是:
x ji − x j
zij = j = 1,2Λ , N
i
其中x j 和σ i 分别是第 i 个变量的平均值和标准差。假定标准化后的变量是 z1,z2,⋯,zD,标准化数据矩阵是
z11z12 Λ z1D
z z Λ z
z =
21 22 2 D
Λ Λ Λ Λ Λ
z N1z N 2Λ zND
首先根据标准化矩阵计算 z1,z2,⋯,zD 的相关矩阵 R,R 一般是协方差矩阵。
1
R = N − 1
Z' Z
然后用 Jacobi 法求 R 的特征值λi 和特征向量 ui(i=1,2,⋯,P) 令(R-λI)u=0,其中 I 为单位矩阵
接着用λi 和 ui 求算主因子载荷矩阵 A。
a11a12 Λ a1D
a a Λ a
A = [a a Λ a ] = a
= 21 22 2K
1 2 k ij
Λ Λ Λ Λ Λ
z D1z D2 Λ zDK
其中 aj=(aij,a2j,⋯adj),j=1,2,⋯,k
a j = • ui
这里 A=aij 则为经过旋转后的综合变量 Fj 与准标化变量 Zi 的相关系数, 即因子载荷。
在实际工作中,主要是根据相关矩阵 R 和主成分特征值λi 的方差贡献及
因子载荷 A 进行区域地理因子及其关联分析。需要说明的是主因子分析的计算结果只是一个中间结果,它只提供了观察地理数据的“最好方向”(采用座标旋转、空间变换技术),尚要结合地理学者的主观思维和经验判断来进行,因此,在应用时应特别“慎重”,尤其是在因子解释过程中。
下面是在分析东北经济区地域系统的空间分异时的主因子计算实例。以东北经济区 175 个县(或县级市)为空间样本,选用 14 个特征参数建立了原始资料矩阵(略)。计算结果如表 5—2,表 5—3。
|
特征值分析 (表 5 — 2 ) |
|||
|---|---|---|---|
|
主成分 |
特征值 |
方差贡献率 |
累积方差贡献率 |
| 1 |
4.3830 |
0.3131 |
0.3131 |
| 2 |
2.9200 |
0.2086 |
0.5216 |
| 3 |
1.5568 |
0.1112 |
0.6328 |
| 4 |
1.2866 |
0.0919 |
0.7247 |
| 5 |
0.9811 |
0.0701 |
0.7948 |
| 6 0.8459 0.0604 0.8552 | |||
| 7 |
0.5594 |
0.0400 |
0.8952 |
| 8 |
0.4414 |
0.0315 |
0.9267 |
| 9 |
0.4047 |
0.0289 |
0.9556 |
|
10 |
0.2166 |
0.0155 |
0.9711 |
|
11 |
0.1505 |
0.0108 |
0.9819 |
|
12 |
0.1171 |
0.0084 |
0.9902 |
|
13 |
0.0834 |
0.0060 |
0.9962 |
|
14 |
0.0534 |
0.0038 |
1.0000 |
从(表 5—2)所得的原始数据相关系数矩阵的特征值、方差贡献率及累积方差贡献率中,可见前 6 个主因子的累积贡献率已达 85.52%,说明主因子所包括的要素信息量可以代表东北经济区地域类型的各方面特征信息(一般≥80%即可),反映出 14 个原始特征参数的大部分信息。
从所得载荷矩阵(表 5—3)中,可以看出原始特征参数与新构造的综合指标之间的相关程度。据此对新变量作出符合区域实际意义的解释。从表 5
—3 中可见,第一主因子载荷中,x2 (种植业产值比重)载荷值最高,其次是 x5(耕地面积比重)和 x11(人口密度)、x12(汉族%),说明第一主因子与 x2、x5、x11、x12 有较高的正相关,另外又与 x4(牧业产值%),x7(草地%),x13(蒙古族%)有较高的负相关。上述结果从地域方面解释说
主成分载荷矩阵表(表 5 — 3 )
|
主成分特征参数 |
1 |
2 |
3 |
4 |
5 | 6 |
|
1.湿润度 |
+0.2168 |
+0.7358 |
+0.2430 | -0.1004 |
-0.0457 |
+0.4416 |
|---|---|---|---|---|---|---|
|
2.种植业% |
+0.8542 |
-0.0299 |
-0.2185 | +0.3258 |
-0.0162 |
-0.0012 |
|
3.林业产值% |
-0.3212 |
+0.4287 |
-0.1295 | -0.4971 |
-0.0314 |
-0.5405 |
|
4.牧业产值% |
0.7484 |
-0.3872 |
+0.3008 | -0.1081 |
-0.0129 |
+0.2352 |
|
5.耕地面积% |
+0.7238 |
-0.5107 |
-0.0344 | +0.0302 |
-0.0596 |
-0.2010 |
|
6.林地面积% |
-0.1137 |
+0.9343 |
+0.0961 | +0.0256 |
+0.0268 |
+0.1440 |
|
7.草地面积% |
-0.7531 |
-0.5140 |
-0.0682 | -0.0640 |
+0.0036 |
-0.0521 |
|
8.工业密度 |
+0.3974 |
-0.1883 |
+0.7866 | -0.0184 |
-0.0457 |
-0.0251 |
|
9.农业密度 |
+0.1718 |
-0.0040 |
+0.0523 | -0.0294 |
+0.9818 |
-0.0257 |
|
10.人均粮食 |
+0.4981 |
-0.2684 |
-0.5275 | +0.2105 |
-0.0183 |
+0.2503 |
|
11.人口密度 |
+0.6065 |
-0.3988 |
+0.6025 | -0.0625 |
-0.0368 |
-0.0736 |
|
12.汉族人% |
+0.6788 |
+0.0120 |
-0.1834 | -0.5901 |
-0.0336 |
+0.0158 |
|
13.蒙族人% |
-0.7534 |
-0.3810 |
-0.0299 | +0.2124 |
+0.0605 |
+0.1063 |
|
14.朝族% |
-0.0855 |
+0.4840 |
+0.1752 | +0.6807 |
0.0266 |
-0.3985 |
明负因子得分是以蓄牧业为主的蒙古族地域占优势,而正因子得分是以种植业为主的高密度汉族地域占优势。反映了东北经济区由西向东的地域大生态农业特征。
第二主因子载荷中,x6(林地%)载荷最高,其次是 x1(湿润度),该结果说明第二主因子与 x6、x1 有较高的正相关,它是划分林业生态经济为主的地域类型的新变量,同时 x6、x1 的组合关系又反映了东北经济区东部湿润森林的生态环境特征。
第三主因子中,工业产值密度(x8)、人口密度(x11)载荷较高,说明
该主因子是反映工业经济地域类型的综合指标,x8 与 x11 的组合关系则反映了工业集中地区的人口高密度性。
第四主因子与朝族人口%有较大正相关,反映了民族分布在东北经济地
域中的地位
第五主因子与农业产值密度有较高的正相关,反映了地域农业经济密度特征。
上述分析结果表明:农业产值密度及其结构、林地面积比重、人口密度、民族构成分布、工业产值度等地域因子,是划分综合地域类型的决定性因子, 基本可以反映出地域类型的自然生态和社会经济特征。
2、区域地理系统的划分
- 聚类分析
聚类分析是新近发展起来的一门多元统计方法,它是根据区域地理变量的属性(特征)的相似性或亲疏程度,用数学方法把它们逐步的分型划类。选择刻划对象间两两接近程度的要素和具体标定方法(分类统计量)是聚类分析的关键性基础工作。聚类分析根据分类对象不同,可分为两类,一类是研究样品之间的关系,称为 Q 型分析,区域地理系统的划分就属于此类;另
一类是研究变量之间的关系,可以对判别要素进行分类研究,通常称为 R 型分析,在具体的区域地理系统划分中,可先进行 R 型分析,选取主要判别因素进行 Q 型分析。
Q 型聚类分析的内容和方法可分为三个部分: 1)原始资料矩阵的构造与数据变换
设有 N 个区域样本,每个样本有 P 项指标(地理要素),则 N 个样本的P 项指标可排成资料矩阵 x:
x11 x12 Λ x1D
x x Λ x
X =
21 22 2 D
Λ Λ Λ Λ Λ
x x Λ x
N1 N 2 ND
为了排除量纲对分类结果的影响,一般需对原始数据进行变换处理,即数据的标准化。标准化方法主要有如下几种(见表 5—4)。
表 5 — 4 几种常见的数据变换方法
|
变换方法 |
变换公式 |
说明 |
|---|---|---|
|
总和标准化 |
X1 = X / ∑X ij ij ij i |
i=1,2 ,N ; j=1,2 ,p(以下不同) ∑X' = 1 ij i |
|
标准差标准化 |
Xij − X j X'ij = S j |
1 X j = N ∑Xij i S = 1 ∑( X − X )2 j m − 1 ij j i X = 0 S' = 1 j j |
|
极差标准化 |
X − min{X } ij i ij X' = ij R j |
max{X ij} min{X ij } R j = − i i 0≤Xij ≤1 |
|
极大值标准化 |
X X' = ij ij max { } i Xij |
max{X' } = 1 i ij 其它各值<1 |
- 常用分类统计量
均质地理系统的划分是以差异性与相似性为基础的。一般距离是区域地理系统之间差异性的测度,相似系数则是相似性的测度。故常用的分类统计量有距离系数和相似系数。(见表 5—5)。
表 5 — 5 几种常见的分类统计量
|
统称 |
计量名 |
计算公式 |
说明 |
||
|---|---|---|---|---|---|
|
距离系数 |
绝对值距离 |
p d ij = ∑ X1k = jk k=1 |
i=j=1 , 2 , N ; K=1 , 2 , , P (下同) |
||
|
欧氏距离 |
d ij = |
1 p ∑(X − X ) 2 |
|||
|
p ik jk k =1 |
|||||
|
明科夫斯基距离 |
p d ij = [∑ Xik − Xjk ] 1/p p k=1 |
p ≥ 1 |
|||
|
切比雪夫距离 |
max d ij = k Xik − Xjk |
||||
|
马氏距离 |
d = ( X − X )∑ −1 ( X − X )' ij i j i j |
∑−1 是各判别要素的方差——协方差矩阵 ∑ 的逆矩阵 |
|||
|
相似系数 |
夹角余弦 |
p ∑Xik • jk k=1 cosθ ij = p p ∑X2 • ∑X2 ik jk k =1 k=1 |
-1 ≤ cos θ ≤ 1 |
||
|
相关系数 |
rij = |
p ∑(Xik − Xi )(X jk − X j k =1 |
|||
|
p p ∑(Xik − Xi )∑ (X jk − X k =1 k= 1 |
|||||
上述几种分类统计量,尤其是距离系数是彼此联系的,如明科夫斯基距离中,当 P=1 时就是绝对值距离,当 P=2 时就是欧氏距离,当 P→∞时,就是切比雪夫距离等。在地理研究中最常用的是欧氏距离和绝对值距离。
- 常用的聚类方法与聚类图的形成
聚类形成的方法一般有两种:一是一次形成法,也称系统聚类,二是逐步形成法,也称动态聚类。它们在区域地理系统划分中都经常使用。但由于一次形成法是根据样本统计量值的大小顺序按保留小号,划掉大号原则进行的,有时难免把不相关的区域样本划到同一类中。而逐步形成法则通过每次组合后重新计算分类统计量矩阵而逐步聚类,克服了一次形成法的缺陷。因此在聚类分析中以应用逐步形成法为好(具体步骤略)。
聚类图的形成一般遵从以下原则。第一,若选出一对样品在已经分好的组中都未出现过,则把它们形成一个独立的新组;第二,若选出两个样品中, 有一个是在已经分好的组中出现过,则把另一个样品也加入到该组中;第三, 若选出一对样品都分别出现在已经分好的两组中,则把这两个组联接在一起;第四,若选出的一对样品出现在同一组中,则这对样品就不用再分组了。
依此反复进行,直到把所有样品都分类聚合完毕为止。
分区或分类数目的确定,是聚类分析的最后步骤。迄今为止仍是一个尚未完全解决的问题,若选取不同的临界水平值(分类统计值),就可分为不同等级层次的区域类型,但总能找到一个局部最优解,也称地理分类阈值。现在对阈值的确定一般是根据谱系图和地理经验进行。阈值可以是单一的统计量,也可以是相邻的统计量区间。另外,也可用统计学的方差检验方法, 对各种分类方案进行显著性检验,选取方差最大者,用以确定分类个数,与之相应的统计量就是分类阈值。可避免人为性和经验性。计算公式为:
∑mi (vi − x)(vi − x)'/T − 1
F = i=1
T ∑
∑ j∈第i类(x j − xi )(x j − x i )'/m − T
式中,T 为分类或分区个数,mi 为归并入第 i 类的样品个数,Vi=(Vi1, Vi2,⋯,Vin)为第 i 类的聚类中心,其分量为
1 ∑
Vik = m j∈第i类x jk ; k = 1,2Λ , no x 为 X 中所有样品总的平均。
这一过程也称为聚类优化,因为它是经对 N-1 分类方案的方差比较得出结果的。
随着数学理论的发展,区划理论的逐步完善和电子计算机的广泛使用, 很多数学聚类方法出现在地理系统区划中,除上述介绍的外,还有模糊聚类、灰色聚类、基于主因子分析的系统聚类(以主因子得分作为聚类数据)等。计算步骤参见第三章中区域地理要素分类的系统聚类步骤。
- 判别分析
判别分析是一种根据样品的各种特征指标或多种信息来分辨或判别某一类型或种属的归属问题的多变量统计分析方法。它与聚类分析不同之点在于:聚类分析不必事先确定类型,类型的形成是聚类分析的结果。而判别分析则需先具备以下条件:第一,已经确定判别要素;第二,已经确定了经验的地理界线或类型数;第三,已经明确了一批典型地理单元的归属。
对区域地理系统进行判别分析的基本原理,是根据已知的地理特征值或变量,按照一定的判别分析准则建立判别函数模型和计算判别临界值(或判别阈值),当求出判别函数值和判别阈值后,再比较其数值的大小,便可确定区域地理系统的归属问题。
在确定判别函数时所使用的准则有多种,如 Fisher 准则、Bayes 准则、Kullback 准则、最小二乘法准则、不确定准则等,但以前两种准则较为常用。
应用 Fisher 准则进行判别分析时,要对原始数据经一定方式进行线性组合,使其形成一个新变量,即判别函数。要使判别函数值能充分的区分开地理类型,就需要使各类均值之间的差别最大,使各类内部的离差平方和最小。换言之,即要求类间(或组间)均值差与类内(或组内)方差之比达到最大, 这样就能把地理类型区分得最清楚。Bayes 准则是另一种思路判别的标准, 它要求把已知的地理数据分成几类或几组,然后计算出未知地理类型或区域归属于各已知类型的概率值,看它归属于哪一类的概率值最大,就把它划归该类;另外还可计算出划归各已知类的错分损失,即看错分哪一类的平均损失为最小,就把它划定为该类,这就是 Bayes 准则的基本要点。
判别分析依其判别类型的多少与方式的不同,可分为两类判别、多类判别和逐步判别等。在这里只介绍存在两种类型情况下的两类判别。对两类判别 Fisher 准则和 Bayes 准则是等价的,但通常应用 Fisher 准则。两类判别可以用于划分地理区的界线,这时,把界线两边视为不同的类型。二级判别同样也可以用于判别多种类型和多条地理界线,只需多次应用这种方法。
依 Fisher 准则,两类判别分析的计算过程由两部分构成。1)构造线性判别函数
一般对于包含 P 个判别因素或变量的线性判别函数其形式为:
y = c1x1 + c 2 x2 +Λ +cD x D = ∑cr x r
r=1
式中 c1、c2、⋯、cD 是待定系数,可以按照使两类之间区别最大,使每一类内部离散性最小的原则,根据判别指标 x1、x2、⋯、xD 的两组 A 与 B 的观测数据来确定。
设我们要判别的两类状态为 A 和 B。对于P 个判别指标,A 类和 B 类各有一批表征数据:
x11(A)、x21(A)、⋯、xD1(A) x12(A)、 x22(A)、⋯、 xD2(A)
⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯ x1n1(A)、 x2n1(A)、⋯、 xDn1(A) x11(B)、 x21(B)、⋯、 xD1(B) x12(B)、 x22(B)、⋯、 xD2(B)
⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯ x1n2(B)、x2n2(B)、⋯、xD2(B)
用y (A)作为 A 类综合指标的重心, y (B)作为 B 类综合指标的重心, 为使判别函数(y)能充分的反映出 A、B 两种地理类型的差别,就要使两类之间的均值差 [y(A) − y(B)]2 最大,而各类内部的商差平方和
n1 n 2
∑[y (A) − y(A)]2 + ∑[y ( B) − y(B)]2 最小。唯此其比值(I)才能达到最大,
i=1 i=1
从而将两类清楚的分开。欲使
[ y(A) − y(B)]2
I = n
n 最大
∑1 [y (A) − y(A)]2 + ∑2 [y ( B) − y( B)]2
i=1 i=1
需使 I 的一阶偏导数等于 0,分别求出 I 对 C1、C2、⋯、CD 的偏导数, 并使其为 0,则得方程组:
∂I = 0
∂c
1
∂I = 0
∂c2
Λ Λ Λ
∂I = 0
∂c
D
从中解出 1、C2、⋯、CD 的数值(过程略),并代入判别函数中。
2)判别与检验
通过判别函数可算出:
D
y(A) = ∑cr x r (A)
r=1 D
y( B) = ∑cr x r (B)
r=1
因为y(A) 和y(B) 分别是用 n1 和 n2 组表征数据求得的,我们取y(A) 和
y(B) 的加权平均作为判别指标或判别阈值。
y = n1 y(A) + n2 y(B)
n1 + n2
若当y(A) > y(B) ,y>yc 归于 A 类时,则 y<yc 归于 B 类。若y(A) <
y(B) ,y<yc 归为 A 类时,则 y>yc 便归为 B 类。
一般为提高判别效果,需从表征数据中挑选出分辩能力较强的若干变量参加建立判别函数。判别分析是假设两组样品取自不同的总体,如果两组多元变量平均值在统计上差异不显著。判别就没有价值。因此,需检验两总体是否有显著差异。检验所用的是以马氏距离为基础所构成的统计量:
F = [
n1n2
(n1 + n 2 )( n1 + n2 − 2)
][ n1 + n 2 − P − 1] × D 2
p
其中 D2 为马氏距离。P 为变量的个数,F 服从自由度为 P 和(n1+n2-P-1) 的 F 分布,n1、n2 分别为总体 A、B 中样品个数,可查 F 分布表进行检验以评价判别函数。
