供应链运营管理中的大数据
要在供应链运营和金融决策中有效地运用大数据,首先需要正确地了解大数据的类型、质量,以及大数据分析和关键能力要素。
大数据类型
数据类型涉及大数据的数据形态和获取的途径和方法,易观智库(2014)在发布的《2014中国供应链大数据市场专题研究报告》中提出:供应链中的大数据主要包括以下四种类型:结构数据、非结构数据、传感器数据和新类型数据。
结构数据是指那些在电子表格或是关系型数据库中储存的数据(Agneeswaran,2012),这一类型的数据只占数据总量的5%左右(Cukier,2010),主要包括交易数据和时间段数据。现在的大数据分析大多以这一类数据为主,很多研究认为这其中重要的结构数据包括ERP数据。YungYun和 Robert(2015)的研究发现,作为高度结构化、集成化的ERP数据能够帮助企业比非ERP数据运用的企业,在战略采购、品类管理和供应商关系管理方面产生更好的绩效。有研究认为ERP 系统数据价值亟须挖掘和拓展(于巧稚,2014)。ERP 系统中存储的数据是企业运转多年的系统积累的大量的行业数据,这些数据对于企业的经营决策和预测来说意义非常重大;另一方面,ERP数据是企业内部处理的结构化数据,在目前大数据时代,企业怎样将自己内部的结构化数据和非结构化数据以及企业内部数据与企业外部数据相衔接,通过运用大数据分析技术深度挖掘这些海量的、类型多样的、具有价值的、实时更新的数据的商业价值,将交互数据、交易数据以及传感器等数据联合以进行价值挖掘,以达到更好的服务客户并提高供应链整体的柔性、稳定性以及效率,是其面临的一个重大挑战(Liska,2015;耿丽丽,2014)。
非结构数据主要包括库存数据、社会化数据、渠道数据以及客户服务数据。尽管现在有大量的研究和报告在探讨数据和分析能力在供应链中的运用(Chae & Olson,2013;Hazen et al.,2014;Trkman,2010),但是这些研究和报告的重点仍然聚焦在传统的数据来源和分析技术以及它们对于供应链的相关计划和执行的影响上面,而对于非结构数据,例如社会化数据对供应链的影响和作用的相关研究却相对缺乏。Natoli(2013)指出,企业可以利用社交媒体数据辅助进行需求预测,抓住消费者需求以便进行更有效的分类计划以及更好地安排商品在货架上的摆放位置。然而,Cecere(2012)对行业领先的企业进行的调查却发现,它们都不能在供应链智能管理中很好地运用社交媒体数据。Natoli在2013年进行的行业调查中也发现,尽管物流供应商、生产者以及零售商们现在都在借力于传统的供应链数据进行供应链的管理,但是参与调查的企业中,只有1%的企业运用了社交媒体数据进行供应链计划。相关研究的缺乏以及企业实践的忽视,充分显示出了大家对社交媒体数据的重要性认识不足,对社交媒体数据的利用不充分(Chae et al.,2014)。Chae等(2014)指出,加强企业对社会媒体数据在供应链情境中的作用的理解非常必要,而对如何利用社交媒体数据来指导企业进行供应链活动的规划(包括新产品的开发、利益相关者的参与、供应链风险管理以及市场探查等) 以及社交媒体数据究竟会对供应链绩效产生怎样的影响这两方面的研究是现在需要关注的重点。要想实现这一目标,就需要从内容丰富的非结构化数据中挖掘出商业智慧,使用不同的研究方法和度量方式(Chau & Xu,2012;Fan & Gordon,2014)。Chae等(2014)以推特数据为例,介绍了从非结构性数据中挖掘商业智慧的三种分析技术,即描述性分析(descriptive analytics,DA)、内容分析(content analytics,CA)以及网络分析(network analytics,NA),指出这三种分析方法从不同的方面分析了非结构数据的特点。
除了上述两种主要的大数据类型外,易观智库(2014)还指出了另外两类数据,即传感器数据和新类型数据:前者主要包括RFID数据、温度数据、QR码以及位置数据。这类数据的量目前增加较快,随着物联网技术的发展将形成新的产业,构建新的物流供应链,为供应链金融带来巨大商机。后者主要有地图数据、视频数据、影像数据以及声音数据等,目前更多用于数据可视化领域。这部分数据使大数据的质量进一步提高,实时性更强,分析的精准度提高。
大数据的质量
Dey和Kumar(2010)指出,企业进行大数据分析所依据的数据往往充满了错误。因此在进行大数据分析的时候需要强调数据的质量问题(Hazen et al.,2014),因为数据的质量对于企业做出的决策有直接的影响(Dyson & Foster,1982;Warth et al.,2011)。甚至还有研究显示,数据质量存在问题会导致企业有形或无形的损失(Batini et al.,2009)。事实上,数据是否可用,在很大程度上是由其质量决定的(O'Reilly,1982),并且,由于现在大数据对供应链管理越来越重要,因此对于高质量数据的需求也变得越来越大(Hazen et al.,2014)。
虽然现在学术上对于什么是高质量的数据还没有一个统一的认识,但是研究认为数据质量的评价应该有多个维度(Ballou and Pazer,1985;Ballou et al.,1998;Pipino,2002;Redman,1996;Wand and Wang,1996;Wang and Strong,1996)。Wang和Strong(1996)以及 Lee 等(2002)都认为数据质量的评价应包括两个部分:数据内在的(intrinsic)要求和情境的(contextual)要求。内在的要求是指数据本身所具有的客观属性,主要包括数据的准确性、及时性、一致性和完整性(Ballou & Pazer,1985;Batini et al.,2009;Blake & Mangiameli,2011;Haug & Arlbjrn,2011;Haug et al.,2009;Kahn et al.,2002;Lee et al.,2002;Parssian,2006;Scannapieco & Catarci,2002;Wang & Strong,1996;Zeithaml et al.,1990)。情境的要求是指数据的质量依赖于数据被观察到和使用的情境,包括关联性(relevancy)、价值增加性(valueadded)、总量(quantity)(Wang & Strong,1996)、可信度(believability)、可及性(accessibility)、数据的声誉(reputation of the data)(Lee et al.,2004,2002)。由于依据低质量数据进行分析决策会给企业造成损失,因此,依赖于大数据做出决策的供应链管理者,应当像对于产出产品的质量一样重视供应链产出的数据质量(Hazen et al.,2014)。Hazen等(2014)根据数据内在质量评价在供应链中的表现进行了举例说明(见表7—1),提出应该进行数据的全面质量管理(TDQM),并指出可以用质量控制图的方式对数据质量进行控制。
表7—1 数据质量评价在供应链中的举例
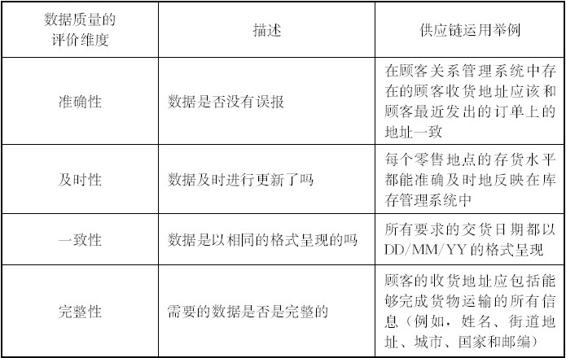 资料来源:Hazen et al.(2014)。
资料来源:Hazen et al.(2014)。
物联网、云计算和大数据分析处理供
应链中大数据的分析也是大数据应用中的核心问题。Waller和Fawcett(2013)指出,大数据分析就是“将多个学科的知识和供应链管理的理论相结合,在考虑数据的质量和可得性的前提下,运用定量和定性的方法来解决供应链管理的相关问题并对相关结果进行预测”。显然,这一分析过程涉及数据的来源物联网、数据分析的基础云计算以及数据的应用大数据分析技术。
物联网利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式联在一起,形成人与物、物与物相联,实现信息化、远程管理控制和智能化的网络。云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算资源共享池(资源包括网络、服务器、存储、应用软件、服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。大数据分析着眼于“数据”,关注实际业务,提供数据采集分析挖掘。这三者之间相互关联、相互作用,物联网是获取大数据的途径和手段,没有物联网,就无法形成真正意义上的大数据;大数据挖掘处理需要云计算作为平台,大数据涵盖的价值和规律能够使云计算更好地与行业应用结合并发挥更大的作用;云计算将计算资源作为服务支撑大数据的挖掘,大数据的发展趋势为实时交互的海量数据查询、分析提供了各自需要的价值信息。
Wong(2012)认为分析学是大数据分析的基础,它能帮助企业做出更好的基于事实的决策从而达到推动战略和提高绩效的终极目标。当然,从大数据的分析中,我们不仅能获得新的见解,还能从中建立相关模型以推断某事发生的概率或是可能性,而这又主要是建立在数据挖掘和统计分析的基础之上。Sanders(2014)指出,大数据如果没有分析学对数据进行解析,那么数据就仅仅只是一堆“数据”而已,并不具有价值。Barton 和 Court(2012)认为高级分析学可能会成为很多产业具有竞争力的重要资产,并且也会成为企业提高其绩效的核心要素。大数据需要分析学,但是要想让分析学崭露头角,仅仅拥有合适的大数据是远远不够的,还必须发展那些关注于商业结果的分析工具。当然,从另外一个角度看,分析学如果没有把大数据作为研究的对象,充其量只是数学和统计的工具和应用方法而已,对于企业也不具有价值和意义,因此,只有大数据和分析学两者结合起来,才会产生巨大的效用和影响。
在具体的数据分析处理上,主要有对静态数据的批量处理,对在线数据的实时处理以及对图数据的综合处理(程学旗, 靳小龙, 王元卓,2014)。其中,对在线数据的实时处理又包括对流式数据的处理和实时交互计算两种。利用批量数据挖掘合适的模式得出具体的含义,制定明智的决策,最终做出有效的应对措施以实现业务目标是大数据批量处理的首要任务。大数据的批量处理系统适用于先存储后计算、实时性要求不高、同时数据的准确性和全面性更为重要的场景。谷歌于 2010年推出了Dremel,引领业界向实时数据处理迈进,实时数据处理是针对批量数据处理的性能问题提出的,可分为流式数据处理和交互式数据处理两种模式。在大数据背景下,流式数据处理源于服务器日志的实时采集,交互式数据处理的目标是将PB级数据的处理时间缩短到秒级。由于自身的结构特征,图可以很好地表示事物之间的关系,在近几年已成为各学科研究的热点。图中点和边的强关联性,需要图数据处理系统对图数据进行一系列的操作,包括图数据的存储、图查询、最短路径查询、关键字查询、图模式挖掘以及图数据的分类、聚类等。
大数据运用能力
供应链大数据运用的能力要求或者说可能遇到的障碍也是目前关注的主要方面,Chae等(2014)分析了数据管理能力、运用科学技术进行计划的能力以及绩效管理能力三者对于提升供应链满意度和运营绩效之间的关系,通过对537家生产工厂收集的数据进行的实证研究发现,数据管理能力是运用数据分析进行供应链决策的关键驱动因素,并指出企业运用大数据进行分析决策之前,必须先要培养企业进行大数据管理的能力。Schoenherr和 Speier-Pero(2015)对于企业使用大数据分析存在的困难进行了问卷调查,发现阻碍企业运用大数据分析的因素主要包括现任的员工不具备运用大数据分析的经验和技能、时间的限制、大数据分析技术与企业现有的运营系统不能整合、对供应链管理缺乏合适的预测性分析解决方案以及对供应链进行大数据分析很难进行操作(见表7—2)。而这其中很重要的一个问题就是缺乏有大数据分析技能的人员,也就是说缺乏大数据分析的相关人才。Waller和Fawcett(2013)认为大数据这类工具不但会改变供应链的设计和管理方式,而且也会给企业和供应链管理带来新的挑战,而挑战的首要一点就是企业需要拥有大数据分析能力并且也有供应链管理相关专业知识的人才(Matthew & Stanley,2013)。吴忠和丁绪武(2013)也指出,在大数据时代,对数据的处理和分析不但已经超出了信息化的范畴,还超出了市场营销的范畴,甚至超出了运营管理的范畴,因此需要具有综合能力的人才。麦肯锡早在其2011年发布的报告中就预言:“到2018年,具有资深分析能力的人才空缺数将达到14万到19万人,并且将有150万人次的管理者和分析家将根据其从大数据分析中得到的发现进行决策。”
表7—2 企业运用大数据分析中遇到的障碍
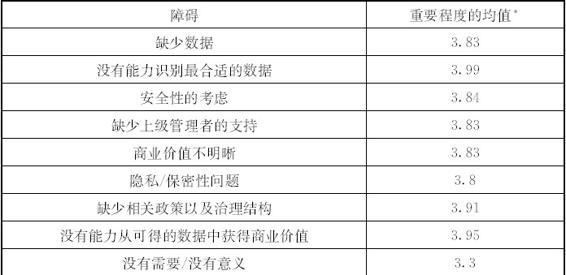
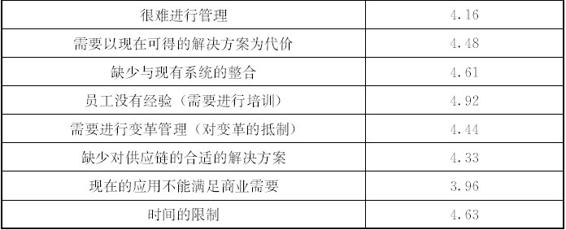 * Schoenherr和 Speier-Pero对531名供应链管理专家进行调查得出的结果,平均值为专家为所有潜在的障碍进行打分而得出的障碍大小均值,打分范围是1~5分,障碍越大,评分越高。
资料来源:Schoenherr & Speier-Pero(2015)。
* Schoenherr和 Speier-Pero对531名供应链管理专家进行调查得出的结果,平均值为专家为所有潜在的障碍进行打分而得出的障碍大小均值,打分范围是1~5分,障碍越大,评分越高。
资料来源:Schoenherr & Speier-Pero(2015)。
对于数据分析家应当具备的技能,Tobias 和Cheri (2015)的调查发现,预测(定量和定性的)、最优化、统计学(估算和抽样的方法)以及经济学(决定机会成本)的相关技能对于大数据分析非常重要。除了这些相关学科技能外,数据操作以及沟通、人际交往的能力对于大数据分析运用也很重要,因为数据操作的技能要求数据工作者不仅能从数据库和资料库中提取交易信息,而且还能从社交网站上获取顾客相关信息并与企业内部的数据进行整合,也就是需要数据工作者对结构性数据和非结构性数据进行整合分析;而对于沟通与交往技能来说,数据工作者不仅需要很好地处理数据,而且也需要将数据中获得的见解有效地传达给相关人员(Schoenherr & Speier-Pero, 2015)。对于供应链管理来说,大数据分析在其中的运用还要求数据工作者具备供应链管理的相关知识(Waller & Fawcett,2013)。总的来看,数据工作者需要具备企业业务流程和决策制定、数据管理以及分析和建模的相关技能(Schoenherr & Speier-Pero, 2015)(见图7—1)。
图7—1 数据工作者应当具备的能力集
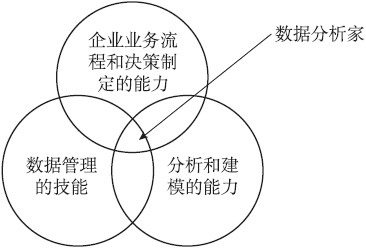 资料来源:Schoenherr & Speier-Pero(2015)。
资料来源:Schoenherr & Speier-Pero(2015)。
