(二)栅格格式向矢量格式的转换
栅格格式向矢量格式转换的目的,是为了将栅格数据分析的结果,通过矢量绘图装置输出,或者为了数据压缩的需要,将大量的面状栅格数据转换为由少量数据表示的多边形的边界。但是更重要的是为了将自动扫描仪获取的栅格数据加入矢量形式的数据库。
多边形栅格格式向矢量格式转换,就是提取以相同编号的栅格集合表示的多边形区域的边界和边界的拓扑关系,并表示成多个小直线段的矢量格式边界线的过程。
栅格格式向矢量格式转换通常包括以下四个基本步骤:
-
多边形边界提取:采用高通滤波将栅格图像二值化或以特殊值标识边界点;
-
边界线追踪:对每个边界弧段由一个节点向另一个节点搜索,通常对每个已知边界点需沿除进入方向的其它 7 个方向搜索下一个边界点,直到连成边界弧段。
-
拓扑关系生成:对于矢量表示的边界弧段,判断其与原图上各多边形的空间关系,形成完整的拓扑结构,并建立与属性数据的联系。
-
去除多余点及曲线圆滑:由于搜索是逐个栅格进行的,必须去除由此造成的多余点记录,以减少数据冗余。搜索结果曲线由于栅格精度的限制可能不够圆滑,需要采用一定的插补算法进行光滑处理。常用的算法有线性叠代法、分段三次多项式插值法、正轴抛物线平均加权法、斜轴抛物线平均加权法、样条函数插值法等。
栅格向矢量转换中最为困难的是边界线搜索、拓扑结构生成和多余点去除。任伏虎等发展了一种栅格数据库数据双边界直接搜索算法( Double Boundary Direct Finding,缩写为 DBDF),较好地解决了上述问题。
双边界直接搜索算法的基本思想是通过边界提取,将左右多边形信息保存在边界点上,每条边界弧段由两个并行的边界链组成,分别记录该边界弧段的左右多边形编号。边界线搜索采用 2×2 栅格窗口,在每个窗口内的四个栅格数据的模式可以唯一地确定下一个窗口的搜索方向和该弧段的拓扑关
系,这一方法加快了搜索速度,拓扑关系也很容易建立。具体步骤如下:
- 边界点和节点提取:采用 2×2 栅格阵列作为窗口顺序沿行、列方向对栅格图像全图扫描,如果窗口内四个栅格有且仅有两个不同的编号,则该四个栅格标识为边界点并保留各栅格所有多边形原编号;如果窗口内四个栅格有三个以上不同编号,则标识为节点(即不同边界弧段的交汇点),保证各栅格原多边形编号信息。对于对角线上栅格两两相同的情况,由于造成了多边形的不连通,也作为节点处理(图 3—26、图 3—27、图 3—28)。
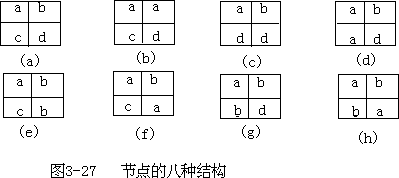
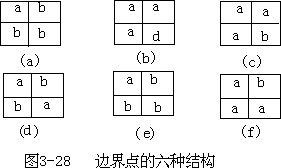
-
边界线搜索与左右多边形信息记录:边界线搜索是逐个弧段进行的,对每个弧段从一组已标识的四个节点开始,选定与之相邻的任意一组四个边界点和节点都必定属于某一窗口的四个标识点之一。首先记录开始边界点组的两个多边形编号作为该弧段的左右多边形,下一点组的搜索方向则由前点组进入的搜索方向和该点的可能走向决定,每个边界点组只能有两个走向,一个是前点组进入的方向,另一个则可确定为将要搜索后续点组的方向。例如图 3-28(c)所示边界点组只可能有两个走向,即下方和右方,如果该边界点组由其下方的一点组被搜索到,则其后续点组一定在其右方;反之, 如果该点在其右方的点组之后被搜索到(即该弧段的左右多边形编号分别为 b 和 a),对其后续点组的搜索应确定为下方,其它情况依次类推。可见双边界结构可以唯一地确定搜索方向,从而大大地减少搜索时间,同时形成的矢量结构带有左右多边形编号信息,容易建立拓扑结构和与属性数据的联系, 提高转换的效率。
-
多余点去除:多余点的去除基于如下思想:在一个边界弧段上连续的三个点,如果在一定程度上可以认为在一条直线上(满足直线方程),则三个点中间一点可以被认为是多余的,予以去除。即满足:
x1 - x2
= x1 - x 3 或 x1 - x3
= x2 - x3
y1 - y2
y1 - y 3 y1 - y3
y2 - y3
由于在算法上的实现,要尽可能避免出现除零情形,可以转化为以下形式:
(x1-x2)(y1-y3)=(x1-x3)(y1-y2)
或
(x1-x3)(y2-y3)=(x2-x3)(y1-y3)
其中(x1,y1),(x2,y2),(x3,y3)为某精度下边界弧段上连续三点的坐标,则(x2,y2)为多余点,可予以去除。
多余点是由于栅格向矢量转换时逐点搜索边界造成的(当边界为或近似为一直线时),这一算法可大量去除多余点,减少数据冗余。
