三、系统聚类分析
虽然数据整理能将大量而复杂的多变量数据适当压缩,但人们还希望进一步减少数据的复杂程度,即将数据定义成一组多变量类别。主成分分析仅仅是数据沿着一条新轴的旋转和投影,得到的新值既大大压缩了原始数据也可以作为新变量使用。主成分分析后的主分量不是按地理空间制图,而是按主成分轴定义的空间制图。当数据在主成分空间的两坐标轴上的分布具有相似性时,这种散射图(常把主成分空间绘制的图称散射图)能够显示出明显的类别特性即聚类特性。如果这些聚类能归纳为分类系统中的某一类的话, 就有可能进一步减少数据的复杂性。另外,这些聚类完全由原始数据的分析中推演而得,就能代表“天然”类别,也比外生分类(按所研究数组的门槛值确定其区间,而不是由数组本身派生出来的区间)和层次分类等人为强加的类别更加真实。
60 年代末到 70 年代初人们把大量精力集中于发展和应用数字分类法, 且将这类方法应用于自然资源、土壤剖面、气候分类、环境生态等数据,形成“数字分类学”学科。目前聚类分析已成为标准的分类技术,在许多大型计算机中都存储了这种分析程序,从 GIS 数据库中将点数据传送到聚类分析程序也不困难。
聚类分析的主要依据是把相似的样本归为一类,而把差异大的样本区分开来。在由 m 个变量组成为 m 维的空间中可以用多种方法定义样本之间的相似性和差异性统计量。
用 xik 表示第 i 个样本第 k 个指标的数据 xjk 表示第j 个样本第k 个指标数据。dij 表示第 i 个样本和第 j 个样本之间的距离,根据不同的需要,距离可以定义为许多类型,最常见、最直观的距离是欧几里德距离,其定义如下:
m
d ij = {[∑(x - x )2 ] / m}1/2
(4 - 4)
k=1
依次求出任何两个点的距离系数 dij(i,j=1,2,⋯,n)以后,则可形成一个距离矩阵:
d11
d 12
d1n
d d d
D = (d ij
) =
21 22 2n
(4 - 5)
d n1
d n2
dnn
它反映了地理单元的差异情况,在此基础上就可以根据最短距离法或最长距离法或中位线法等进行逐步归类,最后形成一张聚类分析谱系图,如图(4
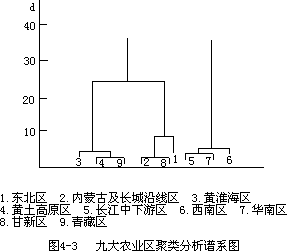 —3)。
—3)。
除上述的欧氏距离外,定义相似程度的还有绝对值距离、切比雪夫距离、马氏距离、兰氏距离、相似系数和定性指标的距离等。
