第四节 主题检索语言
主题检索语言的主要特征是以语词为概念标识,标识词按字顺排列,并用“参照系统”等方法辅助显示概念之间的相互关系。
用主题词作为文献信息标识有以下优点:
-
直观性强。主题词来源于自然语言中,标识比较直观,符合人们的辨识习惯,主题词在词表中按词的字顺排列,其用法如同使用字典、词典,容易掌握,易于利用。
-
专指性高。用作主题词的语词标识经过了全面严格的规范化处理,标识与概念严格对应,标识所表达的概念具有唯一性,故语词对概念的描述具有较强的专指性。
-
灵活性好。主题检索语言的主要特征便是通过词与词之间的概念组配来揭示文献中的各类主题,尤其是后组式的组配原则,便于人们按照检索需要,自由组配检索概念,具有很大的灵活性。
-
网罗性高。一个主题词表达一个事物的概念,若干个主题词合乎逻辑的组配,因此可以形成高度专指的概念特征,用于标引文献时,即可达到高度的概念网罗度。
主题检索语言的优点在于检索人员不必从知识体系的角度去判断所需文献属于什么学科,只要根据课题研究的对象,直接用能表征、描述文献内容的主题词去查检,而且同一篇文献可用多个主题词来标引,因此扩大了检索途径。
常用的主题检索语言主要有标题词语言、叙词检索语言、引文检索语言。一、标题词语言
标题词语言是一种最早出现的按主题来标引和检索文献的传统检索语言。它是以标题词作为文献内容的标识和检索依据。标题词一般分为主标题和副标题两级,标题词在编表时一一列举,而主标题和副标题已固定地组配在一起,间或在标引时再补充组配,所以标题词语言主要是一种先组式的信息检索语言。
标题法的构成原理为以下四点:
-
按主题集中文献;
-
用经过规范化的语词直接标引文献主题;
-
用参照系统间接显示主题之间的相互关系;
-
用字顺序列直接提供主题检索途径。
- 标题词的构成。常用的标题词的类型有两种:
-
单级标题:一个标题仅由一个名词术语构成,可以是一个单词,也可以是一个词组。
-
多级标题:即复合标题,一般采用在主标题后加破折号与副标题、副副标题相结合。
一个标题词要求只代表一个概念,且必须能够直接而精确地表达文献所论及或涉及的主题,以利于提高查准率。
- 标题词的参照系统。标题词是按字顺排列的检索系统,具有直接提供检索途径的优点,但是具有同义关系和相关关系的标题词因字面不同就不能集中在一起,从而造成同性质文献的分散,使相互间关系得不到明确的显示。语义参照系统就是为克服这一缺点而设置的。
-
“见”参照:不用的标题词见用的标题词,它是用来揭示同义词、上位类、下位类的作用的。如“脚踏车见自行车”。脚踏车不是标题词,而自行车是正式标题词。
-
“参见”参照:用以指引检索者从一个采用的标题词去参见与之有关的其它标题词,达到扩大检索途径的目的。这种参照可揭示标题词间的相关关系和等级关系。参见前后的标题词均是正式标题词。
-
注释:当有些标题词概念不十分明确或一形多义时,用圆括弧注释,对该标题词作一简要说明。
- 标题词表的结构。标题词表是规范化的标题词词典,其体系结构一般由下列三个部分组成:
- 编制说明:说明该表的编制经过、收词范围、选词标准、规范化措
施、标题形式、参照系统、标引规则等。
-
主表:是标题词表的主体,包括全部标题词和非标题词,并有参照和注释,按字顺排列,是标引和检索时的主要依据。
-
辅表:是主表的辅助用表,一般用于对主表中的标题词的限定、修饰和复合主表中的标题词。辅表和主表各自分开,组成体系,在标引和检索时相互组配,构成多种标题。
二、叙词检索语言
叙词检索语言是应用较广的主题检索语言之一,它以规范化的名词为基础,吸收了多种检索语言的原理和方法而综合形成的一种主题法语言。叙词语言是采用单元概念的规范化语词的组配来对文献主题进行描述的后组式标引和检索语言,因此,可以说概念组配是它的主要特征。
(一)叙词的特性
-
直观性。叙词使用自然语言中的语词,标识比较直观,按字顺排列, 序列明确,方便检索人员了解和使用。
-
单义性。叙词都是经过规范化处理,以达到一个叙词与一个概念严格对应的要求,故叙词概念明确,易于理解。
-
组配性。连词组配是叙词法的主要特征。叙词较好的检索功能主要来自组配这一特性,检索人员在进行检索时,只要根据检索的需要,临时从词表中选出相应的叙词,按照组配规则,任意组配检索概念,就可达到扩大或缩小检索范围的目的。
(二)叙词的组配
1.组配的数学原理。组配标引是以现代符号逻辑运算为基础,而符号逻辑又是以布尔逻辑代数为基础。布尔逻辑共有三种逻辑运算:
- 逻辑积运算:又称逻辑乘运算,其符号为“AND”或“*”,主要用于概念上具有交叉、限定关系的两个或多个叙词之间的运算。例如某文献系统中含有叙词“医院”的文献有:2,4,5,6,8,17,21(数字表示文献号,下同);含有叙词“信息管理”的文献有:2,3,5,9,16,17,20。要求检索出“医院信息管理”的文献。则可用逻辑积运算表达:
“医院”AND“信息管理”=2,5,17 或者“医院”*“信息管理”=2,5,17
用布尔逻辑运算图表达为图 2:
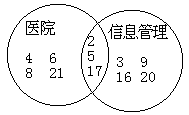
图 2 布尔逻辑图
从上图中可以看出,既含有叙词“医院”又含有叙词“信息管理”的文献共有 3 篇,即两图相交的部分,文献号码为 2,5,17。
逻辑积运算的结果是使概念范围缩小。
- 逻辑和运算:又称逻辑或运算,其符号为“OR”或“+”,是指两个或几个可能相交,也可能不相交的概念的运算。
假定 A 及 B 二个叙词要进行逻辑和运算,即表示在要检索的文献系统中,
凡含有叙词 A 或叙词 B 的文献均命中。同时含有叙词 A 及 B 的文献也命中。如上图:
“医院”=2,4,5,6,8,17,21
“信息管理”=2,3,5,9,16,17,20 则:“医院”+ “信息管理”
=2,3,4,5,6,8,9,16,17,20,21
可见,逻辑和运算是将几个叙词的文献篇数相加(重复者只计一次)。逻辑和运算的结果是使概念范围扩大。
- 逻辑差运算:又称逻辑非运算,其符号为:“NOT”或“一”,是指二个具有从属关系的概念运算。假定 A 及 B 两个叙词要进行逻辑差运算, 则表示在含有叙词 A 的文献集合中去除含有叙词 B 的文献。
逻辑差运算的结果是使概念范围缩小。2.组配原则
-
应恰当地从各学科中选取组配能力强、代表基本概念的科技词汇作叙词来进行组配。
-
叙词组配是概念组配,而不是指单纯的字面组配。3.叙词的概念组配种类
-
概念相交:两个或两个以上具有概念交叉关系的同级叙词进行组配,组配结果形成一个新的概念。
-
概念并列:两个或两个以上具有概念并列关系的同级叙词进行组配。
叙词检索语言所具有的概念组配的特性,使得在具体的检索过程中,可随意扩检和缩检,从而体现了较大的伸缩性、灵活性和适应性,这也是叙词检索语言的主要优点之所在。
三、引文检索语言
引文检索语言是一种新型的信息检索语言,它是利用文献之间的相互引证关系而建立的一种自然语言,其标引词来自文献的主要著录项目。由于它与传统的信息检索语言在内容特点、检索标识、词汇来源等方面有所不同, 因此引起了广大信息界及知识界的关注,并在检索实践中得到了越来越广泛的应用。
(一)引文检索语言的产生和形成
根据引证关系编制信息检索工具源于 19 世纪 70 年代。1873 年美国出版一种称作《谢波德引文》的“法律案例索引”,其方法是以一个案例名称作为标识词,列出引用过该案例的其它一系列案例,一步步串联起大量相关的案例,从而提供众多的办理此类案例资料。20 世纪 50 年代,美国人 E.加菲尔德对这种索引法进行了较深入的研究,并编制了一种专利索引,证明“引文法”的实用性和可行性。直到 1963 年美国《科学引文索引》编辑出版,报
道了 1961 年内出版的 613 种重要科学期刊发表的文献 113318 篇,及其引证
的 1370000 篇文献间的相互引证关系,从而获得巨大成功,也使得《科学引文索引》成为世界上最主要的检索工具之一。
引文检索语言正是利用文献之间的“引证”与“被引证”的关系建立起来的。文献大范围内以“引证”与“被引证”关系串联起具有一定相关程序的“著者网络”和“文献网络”,以此原理出发,进而扩大并研究其中的关系,并对其间的规律性加以阐述和证明,用于文献信息检索工作,即形成独具特色的新型信息检索语言——引文检索语言。
(二)引文检索语言的特点
-
其主要检索标识为被引文献的著者姓名。著者姓名不仅是文献的外形特征,说明某文献由某人撰写,而且从一定意义上说也是文献的内容特性, 即著者姓名也能够说明文献的学科属性。如某人因在某方面的成就而享誉该领域,或者因其特殊的贡献,以其发明、创造等命名,故出现了一些行业中的人名代学科、专业的现象,因此,著者姓名作为一种检索标识在西方图书信息界已较普遍。
-
选词方便。引文检索语言的检索标识词来自文献本身,无需规范,也无需词表。文献撰成时著者即署出姓名,加以标识,所以说文献的标识由著者提供,与文献同时出现在加工标引人员面前,而且著者姓名一般不大变化, 具有较好的稳定性。由于它来自自然语言,可随时从文献中选取。
-
词汇丰富。引文检索语言源于“追溯法”,但优于“追溯法”。它不是以单一文献为起点,而是以一定范围内出版的众多新文献一同多向追溯, 因而联系的文献多,著者多,标识词也多,检索时可随手从加工的文献中选取。它检索面广,易于从较大的范围内发现同性质的文献信息。
(三)引文索引的组成部分
引文索引由三个来源相同的部分组成,但它们具有不同的排列方式。 1.引文索引。列出一段时间发表文献的全部被引文献,按被引文献的第
一著者排列,其下按时间先后列出各被引文献的出处,包括年份、刊名、卷次、页次等,再在各条被引文献之下依次列出引证过它的全部文献。引证款目以第一著者姓名的字顺排列,再列引证文献的出处,包括刊名、卷次、页次、年份等。在引证文献和被引文献的出处部分均不列出篇名。
-
来源索引。是引文索引最基本的部分,因为从另两部分初步查到的线索都要到此部分从篇名上加以核实。这一特点使其类似传统检索工具中正文部分的作用。来源索引按引证著者姓名的字顺排,每个款目可包括姓名、文种代号、篇名、刊名、卷次、期次、页号和发表年份。此外,还列出参考文献的数量和第一著者的联系地址。
-
轮排主题索引。此部分是以文献篇名的关键词轮排主题索引,相当于一般关键词索引,只是在配词时予以限定,以避免过于繁琐。其控制的方法是限定一些词只能作配词而不能作为实词进行搭配,这就相对地减少了一些词的轮排机会,保证索引体积不至臃肿,检出不至过泛,从而保证检索效率的提高。
