分类器的确定
分类器的种类很多,但主要分为两大类:一类是非监督分类,这种分类没有什么先验知识,依据给定的数学模式分出光谱类别,得到结果后再设法将光谱类别逐一地与信息类别挂钩得到可用的结果;另一类是监督分类,监督分类需要有先验知识,利用对所研究地区地类的了解,划分出“训练区域”, 确定判别函数,求出参数,用以“训练”计算机作下一步的分类工作。这种分类得到的结果一般可以直接分出信息类别。
- 非监督分类
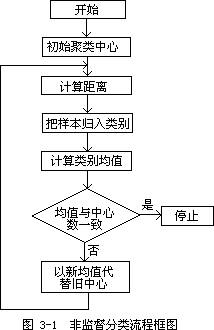
非监督分类按照特征矢量在已选择的特征空间中以类别集群的特点进行分类。非监督分类中常用的方法是聚类法,该方法的主要运算过程如图 3—
n
1所示。距离的计算通常采用欧几里德距离,d = (X
− X ) 2
1/ 2
,即几
ij
k =1
ik jk
何直角空间里两点的直线距离。在实际作聚类时,有时经过多次迭代还不能停止,有时由于数据本身的聚类特性不太好,类别重叠,或一些零散点远离各个聚类中心,或过少的点自成中心等,这些都会影响聚类结果。因此常规定一些附加的约束,以提高分类质量。这些约束主要有:
-
设置一个拒绝类。如果这些点距离各类中心都很远,则属于拒绝类而不被分到某一类中。设拒绝参数为 T 距,dij 为最小距离,且 dij> T 距, 则 Xj 属于拒绝类。
-
类合并。当两个聚集中心过近时,将其并为一类。设距离合并参数为 T 合 1,如果两类均值距离小于或等于 T 合 1,两类合并成一类;若两类均值距离大于 T 合 1,则保留这两类。另一种情况,当分到某一类的像元数过少时, 去掉此类合并到最近的类别中去。设数目合并参数为 T 合 2,计算分类后每类像元数占总像元数的百分比,若百分比小于或等于 T 合 2,寻找距这一类均值距离最近的类别合并;若百分比大于 T 合 2,这一类保留。类别合并后,需要重复计算各类均值矢量。
-
类分裂。有时数据在特征空间某些方向上分布过宽或分布过密,在这一类别中可能不止一个集群中心,这时可以作进一步的分裂。办法仍是检查每一类的像元总数占各类像元总数的百分比。设定一个百分比阈值作为分裂与否的参数 T 分,如果所求百分比中,某值大于或等于这一参数,则对应的类别将被分裂,否则被保留。如果这一类被分裂,要选定两个新的聚类中心。首先计算类别均值矢量 M=(m1,m2,⋯mn)T,以及标准差矢量 S=(σ
1,σ2,⋯,σn)T,则规定新的聚类中心为:
M1=M+S=(m1+σ1,m2+σ2,⋯,mn +σn)T
和
M2=M-S=(m1-σ1,m2-σ2,⋯,mn-σn)T。
上述方法也称为 ISODATA(迭代自组织数据分析或动态聚类)方法。
- 监督分类
在监督分类中,最大似然判别是最常用的一种方法,它假定各类的分布函数为正态,因此,也称为 Bayes 分类。
最大似然分类首先计算像元值矢量 x 属于各类的条件概率(判别函数): P(ωi│x) i=1,2,⋯,m,
ωi 代表第 i 类,共有 m 类。
如果 P(ωi│x)>P(ωj│x) j≠i,j=1,2,⋯,m 成立,则 x
∈ωi。
这样的判决比较合理,或者风险最小,错误概率最小。
根据概率理论中的贝叶斯(Bayes)公式,可以求出条件概率
P(w i
│x = P(w i )P(x│wi )
P(x)
(3—5)
P(x)与类别ωi 无关,对各类来说是一个公共因子,作判别时可将 P
(x)去掉,这时,判别函数 gi(x)= p(x│ωi)p(ωi),判别规则为: 如果
p(x│ωi)p(ωi)>p (x│ωj)p(ωj),j=1,2,⋯,m,j≠i,
则:x∈ωi,式中 p(ωi)是分类图像中类别ωi 出现的概率,可以根据对研究区域的认识来确定,也可以假定各类出现的概率相等;p(x│ωi)是类别ωi 的概率分布,它表示在ωi 这一类别中像元 x 出现的机会。最大似然分类假定各类的分布函数为正态,因此,
p(x│w i ) =
1
(2π) N/ 2 │∑│1/2
1 T −1
exp− 2 (x − Mi ) i (x − Mi )
(3—6)
式中 N 是参加分类的特征数(或波段数),Mi 为均值矢量,Σi 为类别 i 的协方差矩阵,其估计值分别为:
M = 1
i
∑ =
n i
∑Xj j=1
∑[(X
-
M )(x
-
M )T ]
(3—7)
(3—8)
i ni − 1 j=1
j i j i
式中,ni,是类ωi 的像元数目,j 为像元标号,T 为矩阵的转置,Mi 和Σi 可通过对样本像元的数据计算来得出。
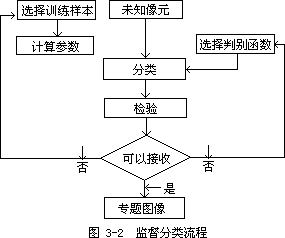
监督分类中除了最大似然法外,还包括最小距离法、平行六面体法等。监督分类的流程如图 3—2 所示。