文件系统阶段
从 50 年代后期到 60 年代中期,数据管理发展到文件系统阶段。此时的计算机不仅用于科学计算,还大量用于管理。外存储器有了磁盘等直接存取的存储设备。在软件方面,操作系统中已有了专门的管理数据软件,称为文件系统。从处理方式上讲,不仅有了文件批处理,而且能够联机实时处理, 联机实时处理是指在需要的时候随时从存储设备中查询、修改或更新,因为操作系统的文件管理功能提供了这种可能。这一时期的特点是:
-
数据长期保留。数据可以长期保留在外存上反复处理,即可以经常有查询、修改和删除等操作。所以计算机大量用于数据处理。
-
数据的独立性。由于有了操作系统,利用文件系统进行专门的数据管理,使得程序员可以集中精力在算法设计上,而不必过多地考虑细节。比如要保存数据时,只需给出保存指令,而不必所有的程序员都还要精心设计一套程序,控制计算机物理地实现保存数据。在读取数据时,只要给出文件名,而不必知道文件的具体的存放地址。文件的逻辑结构和物理存储结构由系统进行转换,程序与数据有了一定的独立性。数据的改变不一定要引起程序的改变。保存的文件中有 100 条记录,使用某一个查询程序。当文件中有
1000 条记录时,仍然使用保留的这一个查询程序。
- 可以实时处理。由于有了直接存取设备,也有了索引文件、链接存取文件、直接存取文件等,所以既可以采用顺序批处理,也可以采用实时处理方式。数据的存取以记录为基本单位。
上述各点都比第一阶段有了很大的改进。但这种方法仍有很多缺点,主要是:
- 数据冗余大。当不同的应用程序所需的数据有部分相同时,仍需建立各自的独立数据文件,而不能共享相同的数据。因此,数据冗余大,空间浪费严重。并且相同的数据重复存放,各自管理,当相同部分的数据需要修改时比较麻烦,稍有不慎,就造成数据的不一致。比如,学籍管理需要建立包括学生的姓名、班级、学号等数据的文件。这种逻辑结构和学生成绩管理所需的数据结构是不同的。在学生成绩管理系统中,进行学生成绩排列和统计,程序需要建立自己的文件,除了特有的语文成绩、数学成绩、平均成绩
等数据外,还要有姓名、班级等与学籍管理系统的数据文件相同的数据。数据冗余是显而易见的,此外当有学生转学走或转来时,两个文件都要修改。否则,就会出现有某个学生的成绩,却没有该学生的学籍的情况,反之亦然。如果系统庞大,则会牵一发而动全身,一个微小的变动引起一连串的变动, 利用计算机管理的规模越大,问题就越多。常常发生实际情况是这样,而从计算机中得到的信息却是另一回事的事件。
- 数据和程序缺乏足够的独立性。文件中的数据是面向特定的应用的,文件之间是孤立的。不能反映现实世界事物之间的内在联系。在上面的学籍文件与成绩文件之间没有任何的联系,计算机无法知道两个文件中的哪两条记录是针对同一个人的。要对系统进行功能的改变是很困难的。如在上面的例于中,要将学籍管理和成绩管理从两个应用合并成一个应用中,则需要修改原来的某一个数据文件的结构,增加新的字段,还需要修改程序,后果就是浪费时间和重复工作。此外,应用程序所用的高级语言的改变,也将影响到文件的数据结构。比如 BASIC 语言生成的文件,COBOL 语言就无法如同是自己的语言生成的文件一样顺利地使用。总之数据和程序之间缺乏足够的独立性是文件系统的一个大问题。
文件管理系统在数据量相当庞大的情况下,已经不能满足需要。美国在60 年代进行阿波罗计划的研究。阿波罗飞船由约 200 万个零部件组成。分散在世界各地制造。为了掌握计划进度及协调工程进展,阿波罗计划的主要合约者罗克威尔(Rockwell)公司曾研制了一个计算机零件管理系统。系统共用了 18 盘磁带,虽然可以工作,但效率极低,维护困难。18 盘磁带中 60% 是冗余数据。这个系统一度成为实现阿波罗计划的严重障碍。应用的需要推动了技术的发展。文件管理系统面对大量数据时的困境促使人们去研究新的数据管理技术,数据库技术应运而生了!例如,最早的数据库管理系统之一IMS 就是上述的罗克威尔(rockwell)公司在实现阿波罗计划中与 IBM 公司合作开发的,从而保证了阿波罗飞船 1969 年顺利登月。
- 数据库系统阶段
从 60 年代后期开始,数据管理进入数据库系统阶段。这一时期用计算机管理的规模日益庞大,应用越来越广泛,数据量急剧增长,数据要求共享的呼声越来越强。这种共享的含义是多种应用、多种语言互相覆盖地共享数据集合。此时的计算机有了大容量磁盘,计算能力也非常强。硬件价格下降, 编制软件和维护软件的费用相对在增加。联机实时处理的要求更多,并开始提出和考虑并行处理。
在这样的背景下,数据管理技术进入数据库系统阶段。
现实世界是复杂的,反映现实世界的各类数据之间必然存在错综复杂的联系。为反映这种复杂的数据结构,让数据资源能为多种应用需要服务,并为多个用户所共享,同时为让用户能更方便地使用这些数据资源,在计算机科学中,逐渐形成了数据库技术这一独立分支。计算机中的数据及数据的管理统一由数据库系统来完成。
数据库系统的目标是解决数据冗余问题,实现数据独立性,实现数据共享并解决由于数据共享而带来的数据完整性、安全性及并发控制等一系列问题。为实现这一目标,数据库的运行必须有一个软件系统来控制,这个系统软件称为数据库管理系统(Database Management System,DBMS)。数据库管理系统将程序员进一步解脱出来,就像当初操作系统将程序员从直接控制
物理读写中解脱出来一样。程序员此时不需要再考虑数据中的数据是不是因为改动而造成不一致,也不用担心由于应用功能的扩充,而导致程序重写, 数据结构重新变动。在这一阶段,数据管理具有下面的特点,这些特点正是数据库的改进之处:
(1)数据结构不是面向单一的应用,而是面向全组织。仍以学校管理为例,要想避免数据冗余和数据程序之间的依赖性,就要将学生学籍及成绩两类不同的数据之间彼此建立关系。如图 1.1。
当需要增加新的应用,比如学生的体质状况管理,则只要再增加新的联系。
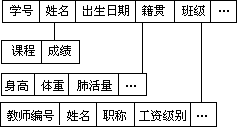
图 1.1 关系化的数据
这种思想只是数据库方法的雏形,它从文件内部的记录的结构比,扩大到不同的文件记录之间建立一种联系。但是它还有局限性,因为它还是从应用的角度去看待数据,还应进一步从整个组织的数据结构考虑。假设所考虑的这个组织——学校,就还应该有教师人事信息、教务信息、教学关系等。不同应用考虑的是整个数据集合的某个有用的子集。整个组织的数据是结构比的。这样描述数据时不仅描述数据本身,还有描述数据之间的联系。
数据的结构化是数据库主要特征之一。这是数库与文件系统的根本区别。至于这种结构化是如何实现的,则与数据库系统采用的数据模型有关, 后面会有较详细的描述。
2.数据冗余小,易扩充。数据库从整体的观点来看待和描述数据,数据不再是面向某一应用,而是面向整个系统。这样就减小了数据的冗余,节约存储空间,缩短存取时间,避免数据之间的不相容和不一致。对数据库的应用可以很灵活,面向不同的应用,存取相应的数据库的子集。当应用需求改变或增加时,只要重新选择数据子集或者加上一部分数据,便可以满足更多更新的要求,也就是保证了系统的易扩充性。
- 数据独立于程序。数据库提供数据的存储结构与逻辑结构之间的映象或转换功能,使得当数据的物理存储结构改变时,数据的逻辑结构可以不变,从而程序也不用改变。这就是数据与程序的物理独立性。也就是说,程序面向逻辑数据结构,不去考虑物理的数据存放形式。数据库可以保证数据的物理改变不引起逻辑结构的改变。
数据库还提供了数据的总体逻辑结构与某类应用所涉及的局部逻辑结构之间的映象或转换功能。当总体的逻辑结构改变时,局部逻辑结构可以通过这种映象的转换保持不变,从而程序也不用改变。这就是数据与程序的逻辑独立性。举例来讲,在进行学生成绩管理时,姓名等数据来自于数据的学籍部分,成绩来自于数据的成绩部分,经过映象组成局部的学生成绩,由数据库维持这种映象。当总体的逻辑结构改变时,比如学籍和成绩数据的结构发
生了变化,数据库为这种改变建立一种新的映象,就可以保证局部数据—— 学生数据的逻辑结构不变,程序是面向这个局部数据的,所以程序就无需改变。
- 统一的数据管理功能,包括数据的安全性控制、数据的完整性控制及并发控制。
数据库是多用户共享的数据资源。对数据库的使用经常是并发的。为保证数据的安全可靠和正确有效,数据库管理系统必须提供一定的功能来保证。
数据库的安全性是指防治非法用户的非法使用数据库而提供的保护。比如,不是学校的成员不允许使用学生管理系统,学生允许读取成绩但不允许修改成绩等。
数据的完整性是指数据的正确性和兼容性。数据库管理系统必须保证数据库的数据满足规定的约束条件,常见的有对数据值的约束条件。比如在建立上面的例子中的数据库时,数据库管理系统必须保证输入的成绩值大于0,否则,系统发出警告。
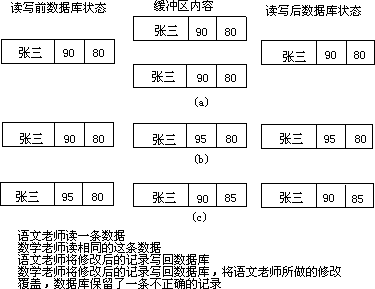
数据的并发控制是多用户共享数据库必须解决的问题。要说明并发操作对数据的影响,必须首先明确,数据库是保存在外存中的数据资源,而用户对数据库的操作是先读入内存操作,修改数据时,是在内存在修改读入的数据复本,然后再将这个复本写回到处存的数据库中,实现物理的改变。比如, 某学生的语文和数学的成绩都有输入错误,语文老师和数学老师同时进行修改。操作流程如图 1.2。
从图中可以看出错误的原因。所以数据库管理系统对数据的并发控制要有一定的限制。数据库管理系统对上述各个方面均提供有效的管理,进一步解放了程序员。
由于数据库的这些特点,它的出现使信息系统的研制从围绕加工数据的程序为中心转变到围绕共享的数据库来进行。便于数据的集中管理,也提高了程序设计和维护的效率。提高了数据的利用率和可靠性。当今的大型信息管理系统均是以数据库为核心的。数据库系统是计算机应用中的一个重要阵地。